The Solver tab contains on the left the Flow Calculation, Batch Settings, and the Parallelization setup and on the right individual tabs for every solver. Tabs corresponding to unused solvers are grayed out and not selectable.
Flow Calculation
FilterDict treats the flow for the first (initial) batch and all subsequent (iterative) batches differently for two main reasons:
In the initial batch, the filter is still clean, while in all iterative batches, previously deposited particles are present.
In all iterative steps, the flow solver can use the solution of the previous step as initial guess, which is not possible for the initial batch.
The names of the equations to solve the Initial Flow PDE and Iterative Flow PDE are shown for information. These entries cannot be changed directly because they depend on the selection of Resolved / Mixed particles in the Constituent Materials tab and the choice of Creeping / Fast Flow in Flow Motion under the Filter Experiment tab.
To solve the Flow PDEs, different flow solvers are available as Initial Flow Solver and as Iterative Flow Solver (SimpleFFT or LIR). The initial flow field may alternatively also be loaded from a previous FilterDict or FlowDict computation.
Tooltips help choosing the appropriate Initial and Iterative Flow Solvers. The default choice is the LIR solver for both the initial and the iterative flow solver. In most cases, LIR is computationally more efficient than SimpleFFT.
Analyze Geometry
If this option is chosen, a geometrical analysis at first determines whether a through path exists and removes unconnected pore components from the computational grid. This may speed up the flow computations but requires time for the geometrical analysis.
Batch Settings
The number of Batches per Flow Field determines how often the flow field is re-computed. Usually, the flow field should be recomputed for every batch (time interval), but if this is numerically too costly, it can be changed to re-compute the flow field only after every second or third batch. However, when more than one batch per flow field is chosen, the accuracy of the result decreases. In this case, numerical artifacts might be introduced. The most accurate results are obtained by computing one batch per flow field.
A batch of particles corresponds to a certain time interval in the experiment. The particles simulated in a batch do not interact with each other, but they do interact with the particles deposited in the previous batches. Decreasing the number of particles per batch leads to a higher accuracy, but also to longer simulation times.
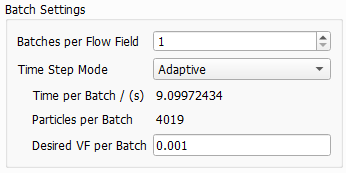
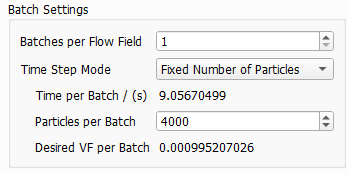
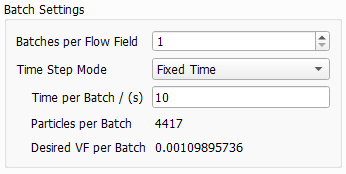
The length of the time intervals per batch and the number of particles can be chosen by selecting a Time Step Mode from the pull-down menu:
The number of particles is determined adaptively in each step. It depends on the desired volume fraction of deposited particles (Desired VF per Batch).
Additionally, FilterDict considers information from the previous steps like, e.g., the particle deposition zone and filter efficiency. Small Desired VF per Batch values correspond to shorter time steps and less particles per batch. Larger values lead to longer time steps and more particles per batch.
The number of particles per batch is determined by the Time per Batch / (s). With a Max. time reached of 100 s chosen as simulation stopping criterion and 10 s chosen as Time per Batch here, the simulation stops after 10 batches of particles.
For multi pass simulations, Fixed Number or Adaptive should be preferred over Fixed Time. The particle concentration in the fluid changes over time. Therefore, also the number of particles could change significantly with Fixed Time steps and this might lead to a less stable simulation.
Parallelization
Depending on the purchased license, the simulation process can be parallelized. The Parallelization Options dialog opens when clicking the Edit... button, to choose between Sequential, Parallel (Shared Memory), Automatic Maximum of Threads and Cluster. For details on how to set up and run parallel computations, refer to the High Performance Computations user guide
The chosen parallelization settings apply for all steps of the simulation. Per default, the Automatic Maximum of Threads option is used, and the exact number of threads depends on the number of cores on the current computer and the number of licensed processes.
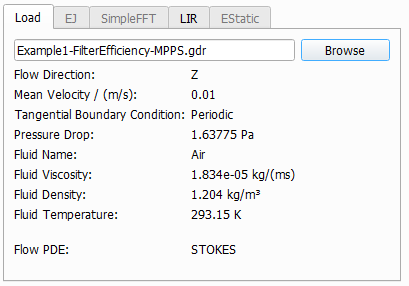
Load
Select Load From File in the Flow Calculation panel as Initial Flow Solver to use a precomputed flow field.The flow field may originate from a FlowDict simulation or from a FilterDict simulation. When calculated with FlowDict, you have to make sure to:
Add inflow and outflow regions to the media model before running FlowDict.
Compute the flow in the Z-direction. You may either use the Stokes or Navier-Stokes equations depending on the flow velocity for this. Make sure that you use the same boundary conditions in FlowDict as you would use in FilterDict.
Set the accuracy at least one order of magnitude higher than the default in FlowDict (e.g., Error Bound = 0.001 instead of 0.01). The stopping criteria depend on global values, whereas the particle movement depends on the local flow field which is subjected to larger deviations.
Under the Load tab, click Browse and choose a result file (GDR) to open. If no flow field is selected, a warning message appears (No flow field chosen) when trying to run the simulation.
The physical properties of the fluid used in the flow simulation are entered automatically when loading the flow GDR file and appear listed under the Load tab.
The Flow direction: Z is the main direction of the flow.
The Mean Velocity (m/s) of the flow field, the used Tangential Boundary Conditions, and the Pressure Drop are taken from the loaded flow simulation. If the flow result was obtained by solving the Stokes equation, the solution is linear and will be rescaled automatically to match the Mean Velocity entered in the Filter Experiment tab.
The fluid parameters Fluid Viscosity (kg/m s), Fluid Density (kg/m³), and Fluid Temperature (K) are the physical values of the fluid used by the solver for the calculation of the flow field.
The fluid settings chosen under the Constituent Materials must be the same as the fluid that was used in the previously run flow simulation, loaded through the GDR file.
Also, the Tangential Boundary Conditions selected in the Filter Experiment tab must match with those used in the flow simulation.
SimpleFFT
The SimpleFFT tab becomes editable when you select the SimpleFFT solver as Initial Flow Solver or Iterative Flow Solver in the Flow Calculation panel.
The stopping criterion Error Bound uses the result of previous iterations, and predicts the final solution based on linear and quadratic extrapolation. The solver stops if the relative difference between computed and predicted solution is smaller than the specified error bound. The stopping criterion recognizes oscillations in the convergence behavior and prevents premature stopping at local minima or maxima. A damped convergence curve is fit through the oscillating curve and the solver stops then regarding the damped convergence curve.
If the Krylov method (under LIR - Advanced Options) is activated, the definition of Error Bound is somewhat different. Here, no prediction is made, instead the continuity between neighboring cells and the conservation of mass is checked. The maximal value is normalized by the mean flow and if this value is smaller than the Error Bound the simulation stops.
The Tolerance stopping criterion looks for stagnation of the method when the process becomes stationary, i.e., the improvement in the pressure drop value becomes extremely small from iteration to iteration.
In each iteration, the solver checks for the current computed value against the values of the last 100 iterations if there are any changes.
(327)
The computation is stopped if the maximal relative change is smaller than the value entered for Tolerance. When there is doubt about the quality of the solution, decrease the Tolerance value by a factor of ten. The drawback of this criterion is that the solver sometimes might stop too early in case of slow convergence rate or at local extrema of oscillatory convergence curves.
When the Residual stopping criterion is used, the iteration is stopped if the solution satisfies the equation up to the required accuracy.
By setting the stopping criterion to Residual, the computations terminate as soon as the relative norm drops below the selected residual threshold. The relative norm of the Schur Complement residual is computed and displayed in the console window during the calculations. The console is visible by clicking the double arrow button on the lower right corner in the progress dialog.
The recommendation to choose Tolerance or Residual for the EJ solver is based on the structure’s porosity. Both give similar results for highly porous structures. For dense structures, if using the Schur Complement Residual, the relative norm of the residual may be small even though the correct pressure drop has not been reached. So, when in doubt, use the Tolerance criteria – the default option.
Be aware that the default accuracy in FilterDict is one order of magnitude higher than in FlowDict. The stopping criteria depend on global values, whereas the particle movement depends on the local flow field. It is therefore necessary to make sure that not only the overall pressure drop is computed up to the given accuracy, but that also the local values are sufficiently accurate. This typically achieved by setting a higher accuracy as stopping criterion.
Use the Maximum Iterations value or the Maximum Run Time (h) stopping criteria causes the solver to stop if the maximal number of iterations and/or the maximal runtime (in hours) is exceeded.
When the solver stops because one of these criteria has been reached, no guarantee on the quality of solution can be given. In this case, a warning is printed into the report. The following possibilities might help:
Check the corresponding .log file to see how large the residual values and the pressure drop values are. If the pressure drop values are in reasonable range and they do not have changed during the last iterations, you may decide to use the current result.
Double-check the structure and parameter values. Unphysical parameters or too rough resolution of the structure (leading, e.g., to artificial unconnected components) can cause an iterative solver to fail.
The tridiagonal matrix algorithm (Tdma), also known as the Thomas Algorithm, may help to improve the convergence for high porosity structure, especially for Navier-Stokes. The algorithm transforms the 3D flow problem to 2D. Thus, it leads to a shorter runtime and increases the convergence speed.
Three options can be chosen from the pull-down menu: Automatic, NotUse Tdma or Use Tdma.
If Automatic is selected, the SimpleFFT solver decides if Tdma will be used, regarding the porosity of the structure. Thus, Tdma is used if the porosity is high. For most cases it is recommended to choose Automatic.
If a message dialog appears, displaying that NaN is detected in iterations, NotUse Tdma should be tried.
If the structures porosity is very high, it might decrease the runtime a little bit to explicitly choose Use Tdma. But for most cases Automatic will work well.
For more information about the Thomas algorithm see here.
Depending on the material parameters and geometrical structure of the structure, the underlying mathematical problem can vary in complexity, thus influencing the behavior of the solver. This is directly related to the Reynolds number, an indication of the complexity of the flow solver computations. The higher the Reynolds number, the more Stable the flow solver settings should be, resulting in higher number of iterations, slower time stepping, and longer flow solver run times. However, making the solver run less iterations and, thus, faster (Fast), implies the risk that the solver does not converge.
For the SimpleFFT solver, the management of this balance is done through the Velocity relaxation: Stable ↔ Fast and Pressure relaxation: Stable ↔ Fast slide bars.
Setting the balance of Stable versus Fast is a trial-and-error process. Although there is no general rule to optimize it, the log files and the visualization of the structure might help finding the balance. Non-sense structure visualization results indicate that a more stable, slower solver is needed.
LIR
The LIR tab becomes editable when you select the LIR solver as Initial Flow Solver or Iterative Flow Solver in the Flow Calculation panel.
The stopping criterion Error Bound uses the result of previous iterations, and predicts the final solution based on linear and quadratic extrapolation. The solver stops if the relative difference between computed and predicted solution is smaller than the specified error bound. The stopping criterion recognizes oscillations in the convergence behavior and prevents premature stopping at local minima or maxima. A damped convergence curve is fit through the oscillating curve and the solver stops then regarding the damped convergence curve.
If the Krylov method (under LIR - Advanced Options) is activated, the definition of Error Bound is somewhat different. Here, no prediction is made, instead the continuity between neighboring cells and the conservation of mass is checked. The maximal value is normalized by the mean flow and if this value is smaller than the Error Bound the simulation stops.
The Tolerance stopping criterion looks for stagnation of the method when the process becomes stationary, i.e., the improvement in the pressure drop value becomes extremely small from iteration to iteration.
In each iteration, the solver checks for the current computed value against the values of the last 100 iterations if there are any changes.
(327)
The computation is stopped if the maximal relative change is smaller than the value entered for Tolerance. When there is doubt about the quality of the solution, decrease the Tolerance value by a factor of ten. The drawback of this criterion is that the solver sometimes might stop too early in case of slow convergence rate or at local extrema of oscillatory convergence curves.
Be aware that the default accuracy in FilterDict is one order of magnitude higher than in FlowDict. The stopping criteria depend on global values, whereas the particle movement depends on the local flow field. It is therefore necessary to make sure that not only the overall pressure drop is computed up to the given accuracy, but that also the local values are sufficiently accurate. This typically achieved by setting a higher accuracy as stopping criterion.
Use the Maximum Iterations value or the Maximum Run Time (h) stopping criteria causes the solver to stop if the maximal number of iterations and/or the maximal runtime (in hours) is exceeded.
When the solver stops because one of these criteria has been reached, no guarantee on the quality of solution can be given. In this case, a warning is printed into the report. The following possibilities might help:
Check the corresponding .log file to see how large the residual values and the pressure drop values are. If the pressure drop values are in reasonable range and they do not have changed during the last iterations, you may decide to use the current result.
Double-check the structure and parameter values. Unphysical parameters or too rough resolution of the structure (leading, e.g., to artificial unconnected components) can cause an iterative solver to fail.
The LIR solver uses a very memory efficient adaptive grid structure for the simulations.
If the option Write Compressed Volume Fields is checked, then the adaptive grid is used as compression method for writing out *.vap files. This option allows to save 80-90% space on hard drive. The runtime for writing *.vap files is also reduced significantly. But the runtime for loading and uncompressing of compressed *.vap is increased by the amount of runtime that was saved for writing out compressed *.vap files.
If the option Write Compressed Volume Fields is not checked, then a usual regular grid is used for writing out *.vap files.
The Multigrid Method (see, e.g., Wesseling, 2004) was introduced to speed-up the computation and reduce the runtime significantly. The main idea of Multigrid is the usage of multiple coarser adaptive grids to speed up convergence behavior but requires only little more memory.
The method is available to solve the Stokes and Stokes–Brinkman equations as well as for solving mechanics, diffusion, thermal, and electrical conduction and is enabled by default.
Another speed-up option to accelerate the convergence behavior of the LIR solver is called Krylov Subspace Method.
The runtime of the LIR solver depends on many different properties of the structure and the simulation parameters. The BiCGStab algorithm is used, which can reduce the runtime for challenging simulation very drastically.
Note! Using the BiCGStab method approximately doubles the amount of RAM needed for the computation.
Unfortunately, the Krylov method is not always faster than a simulation without the Krylov method and therefore we introduced an Automatic mode which uses some heuristics to choose the most efficient method based on structure, material parameters, and boundary conditions automatically. Of course, it is possible to explicitly enable (Enabled) or disable (Disabled) the method.
Note! In case that the Krylov subspace method (BICGStab) is used, the Relaxation may also be adapted automatically.
Depending on the material parameters and geometry of the structure, the underlying mathematical problem can vary in complexity, thus influencing the behavior of the solver. The more complex the problem is, the more stable the solver settings should be.
With the Relaxation number, the solver is adjusted from Stable (which results in higher number of iterations, slower time stepping, and longer solver run times), to Fast, which makes the solver run less iterations but implies the risk that the solver does not converge. The Relaxation is a parameter of the SOR method and must be between 0 and 2 to ensure convergence. For relaxation values smaller than one (<1.0), the simulation is more stable. For relaxation values larger than one (>1.0), the simulation converges faster.
The LIR solver can Optimize forSpeed or Memory.
If Speed is chosen, the solver constructs additional optimization structures. The runtime is decreased by up to 30% but requires up to 50% more memory compared to the other option.
If Memory is chosen, the runtime is increased by up to 40% but the solver requires up to 50% less memory.
The Grid Type decides what kind of tree structure is used for the simulation.
The default option is LIR-Tree and should always be used. The solver uses an adaptive grid structure called LIR-tree and needs up to 10 times less runtime and memory compared to the Regular Grid option.
The solver can analyze the result field during the computation and improves the adaptive grid in places where more accuracy is needed. The LIR solver splits cells where a high gradient occurs.
The solver can analyze the computed field and refines the adaptive grid during the computation at locations where more accuracy is needed. The LIR solver splits cells where a high gradients occur when the Grid Refinement Method is enabled. In this case, the additional parameters Number of Grid Refinements, Allow Sub-Voxel Resolution, and Allow Grid Re-Coarsening become available.
Select one of the three available refinement methods from the drop-down menu.
When A Posteriori Error Bound is selected, the solver targets the specified accuracy Threshold. While the Error Bound (set as Simulation Stopping Criterion)determines the relative error in the solution of the linear system, A Posteriori Error Bound refers to the relative error estimated by comparing high-order and low-order discrete solutions. The accuracy Threshold refers to the relative error to the analytical solution and the value must be between 0.0 and 1.0.
Choosing Difference (Automatic) leads to computational cells being split when the difference in values between neighboring cells exceeds a certain Threshold. The solver automatically chooses all internal parameters based on the structure and simulation settings. For this option, cells are split where the current gradient is greater than the Threshold multiplied by the maximum gradient, where the threshold is determined automatically.
Selecting Difference (Manual) also causes the computational cells to be split when the difference in values between neighboring cells exceeds the specified Threshold. You can specify all parameters (Threshold and Number of Grid Refinements) for the grid refinement manually. For this option, cells are split where the current gradient is greater than the Threshold multiplied by the maximum gradient. The Threshold value must be between 0.0 and 1.0. The recommended value range is between 0.05 and 0.1.
Activate Reynolds Grid Refinement to use the local Reynolds number (Re) for adaptive grid refinement.
A grid cell is split if the local Reynolds number, i.e., the ratio between inertial and viscous forces exceeds the given threshold. The Reynolds number is defined as:
(328) Reynolds Number
where is the density of the fluid (SI units: kg/m3), u is the velocity of the fluid (m/s), is the dynamic viscosity of the fluid (Pa·s or N·s/m2 or kg/m·s), L is a characteristic length (m). For the local Reynolds number, the size of the grid cell is used for the characteristic length.
The Number of Grid Refinements controls the maximum number of grid refinements that the solver can perform during the simulation. The value should be set between 0 and 10, where a value of 0 means that no grid refinements will be made. Grid refinements may increase the number of iterations, runtime, and memory requirements.
When Allow Sub-Voxel Resolution is enabled, the solver is allowed to split computational cells to sizes smaller than the voxel length.
This feature is beneficial for low-porosity structures for which the pore throats require finer resolution or for modeling fast Navier-Stokes flows with strong vortices.
Enabling this feature may increase the number of iterations, runtime, and memory requirements.
Check Allow Grid Re-Coarsening to allow the solver to automatically revert the grid refinement and coarsen the computational cells.
This means, grid refinement is done temporarily. Afterwards, the cells are merged as soon as accuracy is not needed anymore. This reduces the memory and runtime requirements.
 Simulation Stopping Criterion: Error Bound, Tolerance, and Residual
Simulation Stopping Criterion: Error Bound, Tolerance, and Residual




